" height="19.6944px" id="tMAW2sL8r" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.5" stroke="rgb(26, 32, 117)" transform="translate(1.004 1)" width="33.99999375px"/><path d="M 16.945 0 L 16.945 17.958 L 0 27.805 L 0 9.847 Z" fill="rgb(227, 227, 240)" height="27.805370000000003px" id="JJvaBmqTN" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.5" stroke="rgb(26, 32, 117)" transform="translate(18.055 10.652)" width="16.9455px"/><path d="M 17.055 9.847 L 17.058 27.805 L 0.004 17.958 L 0 0 Z" fill="rgb(255, 255, 255)" height="27.80527px" id="sJy5K17qe" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="0.5" stroke="rgb(26, 32, 117)" transform="translate(1 10.652)" width="17.058135968px"/></svg>)
" width="36px"><path d="M 0 36 L 0 0 L 36 0 L 36 36 Z" fill="transparent" height="36px" id="WHJWN5TkH" width="36px"/><path d="M 0 9.375 L 6.72 9.375 C 6.504 6.094 5.589 2.898 4.035 0 L 2.685 0 C 1.131 2.898 0.216 6.094 0 9.375 Z" fill="rgb(26, 32, 117)" height="9.374994000000001px" id="D4GeQFLRH" transform="translate(14.639 7.5)" width="6.71992200000002px"/><path d="M 4.905 8.805 C 5.079 5.762 5.812 2.778 7.065 0 C 5.171 0.642 3.5 1.812 2.249 3.372 C 0.997 4.932 0.217 6.817 0 8.805 Z" fill="rgb(26, 32, 117)" height="8.804988000000002px" id="jmtvry3iu" transform="translate(7.495 8.07)" width="7.065000000000022px"/><path d="M 2.1 8.805 L 7.005 8.805 C 6.793 6.824 6.022 4.944 4.782 3.385 C 3.541 1.826 1.883 0.652 0 0 C 1.233 2.782 1.945 5.766 2.1 8.805 Z" fill="rgb(26, 32, 117)" height="8.804988000000002px" id="IFfmxrmym" transform="translate(21.488 8.07)" width="7.005060000000025px"/><path d="M 2.16 0 C 1.986 3.043 1.254 6.027 0 8.805 C 1.894 8.162 3.565 6.993 4.817 5.433 C 6.068 3.873 6.848 1.988 7.065 0 Z" fill="rgb(26, 32, 117)" height="8.805060000000001px" id="NQ7dQhyno" transform="translate(21.431 19.125)" width="7.065000000000019px"/><path d="M 4.905 0 L 0 0 C 0.212 1.981 0.983 3.861 2.224 5.42 C 3.464 6.979 5.122 8.153 7.005 8.805 C 5.772 6.023 5.06 3.039 4.905 0 Z" fill="rgb(26, 32, 117)" height="8.805060000000001px" id="KE2e9uCl_" transform="translate(7.495 19.125)" width="7.005005999999958px"/><path d="M 6.72 0 L 0 0 C 0.223 3.28 1.138 6.475 2.685 9.375 L 4.035 9.375 C 5.589 6.477 6.504 3.281 6.72 0 Z" fill="rgb(26, 32, 117)" height="9.374939999999999px" id="DgtH1M3F6" transform="translate(14.639 19.125)" width="6.71992200000002px"/><path d="M 2.25 0 C 1.805 0 1.37 0.132 1 0.379 C 0.63 0.626 0.342 0.978 0.171 1.389 C 0.001 1.8 -0.044 2.253 0.043 2.689 C 0.13 3.125 0.344 3.526 0.659 3.841 C 0.974 4.156 1.375 4.37 1.811 4.457 C 2.247 4.544 2.7 4.499 3.111 4.329 C 3.522 4.158 3.874 3.87 4.121 3.5 C 4.368 3.13 4.5 2.695 4.5 2.25 C 4.5 1.653 4.263 1.081 3.841 0.659 C 3.419 0.237 2.847 0 2.25 0 Z" fill="rgb(26, 32, 117)" height="4.4999981102994px" id="yz2qIzO5V" transform="translate(15.75 0)" width="4.499998110299384px"/><path d="M 2.25 0 C 1.805 0 1.37 0.132 1 0.379 C 0.63 0.626 0.342 0.978 0.171 1.389 C 0.001 1.8 -0.044 2.253 0.043 2.689 C 0.13 3.125 0.344 3.526 0.659 3.841 C 0.974 4.156 1.375 4.37 1.811 4.457 C 2.247 4.544 2.7 4.499 3.111 4.329 C 3.522 4.158 3.874 3.87 4.121 3.5 C 4.368 3.13 4.5 2.695 4.5 2.25 C 4.5 1.653 4.263 1.081 3.841 0.659 C 3.419 0.237 2.847 0 2.25 0 Z" fill="rgb(26, 32, 117)" height="4.500013446863562px" id="J33nzg30y" transform="translate(15.75 31.5)" width="4.499998110299384px"/><path d="M 3.871 0.667 C 3.554 0.35 3.151 0.133 2.711 0.044 C 2.271 -0.044 1.815 0 1.401 0.171 C 0.986 0.342 0.632 0.633 0.382 1.005 C 0.133 1.378 0 1.817 0 2.265 C 0 2.713 0.133 3.152 0.382 3.525 C 0.632 3.897 0.986 4.188 1.401 4.359 C 1.815 4.53 2.271 4.574 2.711 4.486 C 3.151 4.397 3.554 4.18 3.871 3.862 C 4.289 3.436 4.524 2.863 4.524 2.265 C 4.524 1.667 4.289 1.094 3.871 0.667 Z" fill="rgb(26, 32, 117)" height="4.5299983854213535px" id="o3Jdq1LcG" transform="translate(26.859 4.598)" width="4.523940000000028px"/><path d="M 3.871 0.668 C 3.554 0.35 3.151 0.133 2.711 0.044 C 2.271 -0.044 1.815 0 1.401 0.171 C 0.986 0.342 0.632 0.633 0.383 1.005 C 0.133 1.378 0 1.817 0 2.265 C 0 2.714 0.133 3.152 0.383 3.525 C 0.632 3.897 0.986 4.188 1.401 4.359 C 1.815 4.53 2.271 4.574 2.711 4.486 C 3.151 4.397 3.554 4.18 3.871 3.863 C 4.289 3.436 4.524 2.863 4.524 2.265 C 4.524 1.667 4.289 1.094 3.871 0.668 Z" fill="rgb(26, 32, 117)" height="4.530084132375148px" id="XDC7YK0d4" transform="translate(4.598 26.872)" width="4.523904000000017px"/><path d="M 4.5 2.25 C 4.5 1.805 4.368 1.37 4.121 1 C 3.874 0.63 3.522 0.342 3.111 0.171 C 2.7 0.001 2.247 -0.044 1.811 0.043 C 1.375 0.13 0.974 0.344 0.659 0.659 C 0.344 0.974 0.13 1.375 0.043 1.811 C -0.044 2.247 0.001 2.7 0.171 3.111 C 0.342 3.522 0.63 3.874 1 4.121 C 1.37 4.368 1.805 4.5 2.25 4.5 C 2.847 4.5 3.419 4.263 3.841 3.841 C 4.263 3.419 4.5 2.847 4.5 2.25 Z" fill="rgb(26, 32, 117)" height="4.499998110299398px" id="asAn08OfD" transform="translate(31.5 15.75)" width="4.5000134468635675px"/><path d="M 4.5 2.25 C 4.5 1.805 4.368 1.37 4.121 1 C 3.874 0.63 3.522 0.342 3.111 0.171 C 2.7 0.001 2.247 -0.044 1.811 0.043 C 1.375 0.13 0.974 0.344 0.659 0.659 C 0.344 0.974 0.13 1.375 0.043 1.811 C -0.044 2.247 0.001 2.7 0.171 3.111 C 0.342 3.522 0.63 3.874 1 4.121 C 1.37 4.368 1.805 4.5 2.25 4.5 C 2.847 4.5 3.419 4.263 3.841 3.841 C 4.263 3.419 4.5 2.847 4.5 2.25 Z" fill="rgb(26, 32, 117)" height="4.499998110299398px" id="MCcs4r2LC" transform="translate(0 15.75)" width="4.5px"/><path d="M 3.862 3.871 C 4.18 3.554 4.397 3.151 4.486 2.711 C 4.574 2.271 4.53 1.815 4.359 1.401 C 4.188 0.986 3.897 0.632 3.525 0.383 C 3.152 0.133 2.714 0 2.265 0 C 1.817 0 1.378 0.133 1.005 0.383 C 0.633 0.632 0.342 0.986 0.171 1.401 C 0 1.815 -0.044 2.271 0.044 2.711 C 0.133 3.151 0.35 3.554 0.667 3.871 C 1.094 4.289 1.668 4.524 2.265 4.524 C 2.863 4.524 3.436 4.289 3.862 3.871 Z" fill="rgb(26, 32, 117)" height="4.52394px" id="Fy2le1HRj" transform="translate(26.873 26.864)" width="4.529997332022967px"/><path d="M 3.863 3.871 C 4.18 3.554 4.397 3.151 4.486 2.711 C 4.574 2.271 4.53 1.815 4.359 1.401 C 4.188 0.986 3.897 0.632 3.525 0.383 C 3.152 0.133 2.713 0 2.265 0 C 1.817 0 1.378 0.133 1.005 0.383 C 0.633 0.632 0.342 0.986 0.171 1.401 C 0 1.815 -0.044 2.271 0.044 2.711 C 0.133 3.151 0.35 3.554 0.668 3.871 C 1.094 4.289 1.667 4.524 2.265 4.524 C 2.863 4.524 3.436 4.289 3.863 3.871 Z" fill="rgb(26, 32, 117)" height="4.523904000000001px" id="oUwiWstd4" transform="translate(4.598 4.589)" width="4.530001661593019px"/></g></svg>)
" height="36px" id="scAYi6Xom" transform="translate(2.995 2)" width="29.9999532385908px"/></svg>)


Written by
Published on
TL;DR: The methodology for extracting high performance is changing with AI. Gone are the days of software abstractions, rapidly being replaced by agentic code generation. An automated performance engineering stack has become necessary to adapt to new models, algorithms, and hardware.
Introduction
A few weeks ago, I was invited to speak at the Frontiers of AI Summit, joined by a stellar lineup of founders and researchers across academia and industry. This gave me the opportunity to present Makora’s vision on AI performance engineering, bringing together the different technologies and products that we have been developing over the past 2 years. The talk was also recorded and made available publicly for people to watch. This blog post will summarize the talk and expand upon some of its main points, laying a foundation for Makora’s approach to AI performance engineering.
Software Abstractions → Agentic Code Generation
AI is advancing at a pace that is difficult for traditional software stacks to match. Models are growing larger, workloads are becoming more diverse, and hardware platforms are evolving rapidly across GPUs, accelerators, memory systems, and datacenter-scale interconnects. Yet the performance of AI systems still depends heavily on low-level software: kernels, schedules, memory layouts, communication patterns, and hardware-specific optimizations.
This creates a widening gap. On one side, hardware vendors continue to expose increasingly powerful capabilities. On the other, most developers and even many performance engineers cannot manually keep up with the complexity needed to fully exploit them. The traditional solution to this problem involves building easy-to-program software abstractions and compilers to access hardware performance. The central argument of this talk is that the next generation of AI infrastructure will require a new approach: automatic GPU performance engineering is powered by agentic code generation and automatic search.
Why is AI Performance Engineering difficult?
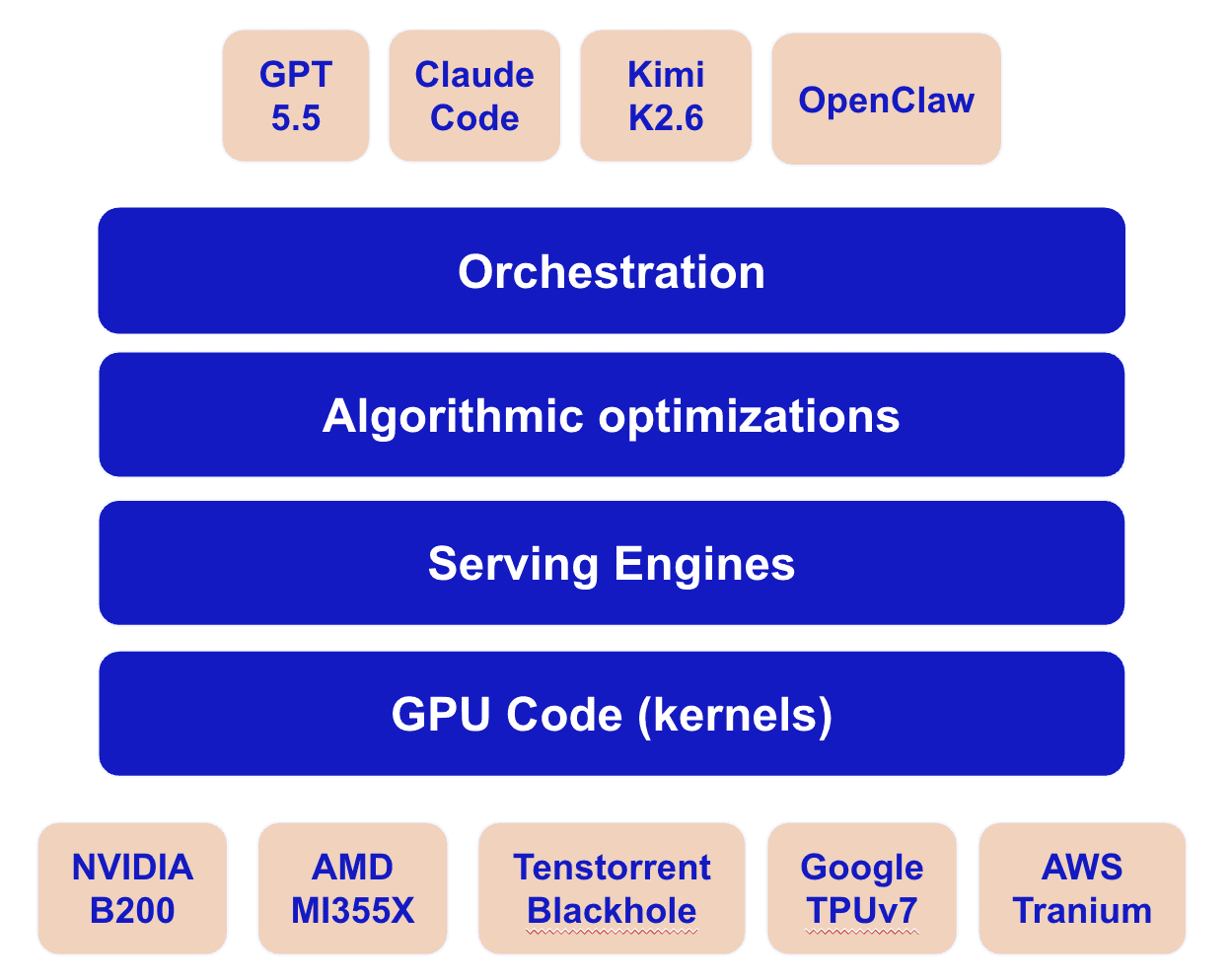
The AI performance engineering stack contains multiple layers, all of which are challenging to manually optimize and tune for performance. In the following subsections, we outline the challenges at three layers of the AI software stack: GPU code, serving engines, and algorithms.
GPU Code (Kernels)
At the lowest level, low-level code is needed to program different types of accelerators, from CPUs, to GPUs, and specialized AI accelerators. Heterogeneity has become a reality for high performance AI workloads, making the ability to target multiple hardware types crucial to achieve the best performance/$. However, low-level code is notoriously difficult to write, exacerbated by the fast hardware release cycle, and rapidly-changing AI workloads. For example, NVIDIA B200 matrix units can only be accessed using the tcgen05 PTX instruction, and it is neither forward nor backward compatible with other NVIDIA GPUs. This makes the update of low-level code a large and time-consuming burden, that delays the use of new AI chips. A well-known example is the Flashattention4 (FA4) kernels that are necessary for the deployment of all transformer-based AI models. However, FA4 took months for release after the B200 GPUs were already installed, causing servers to sit idle for weeks or months.
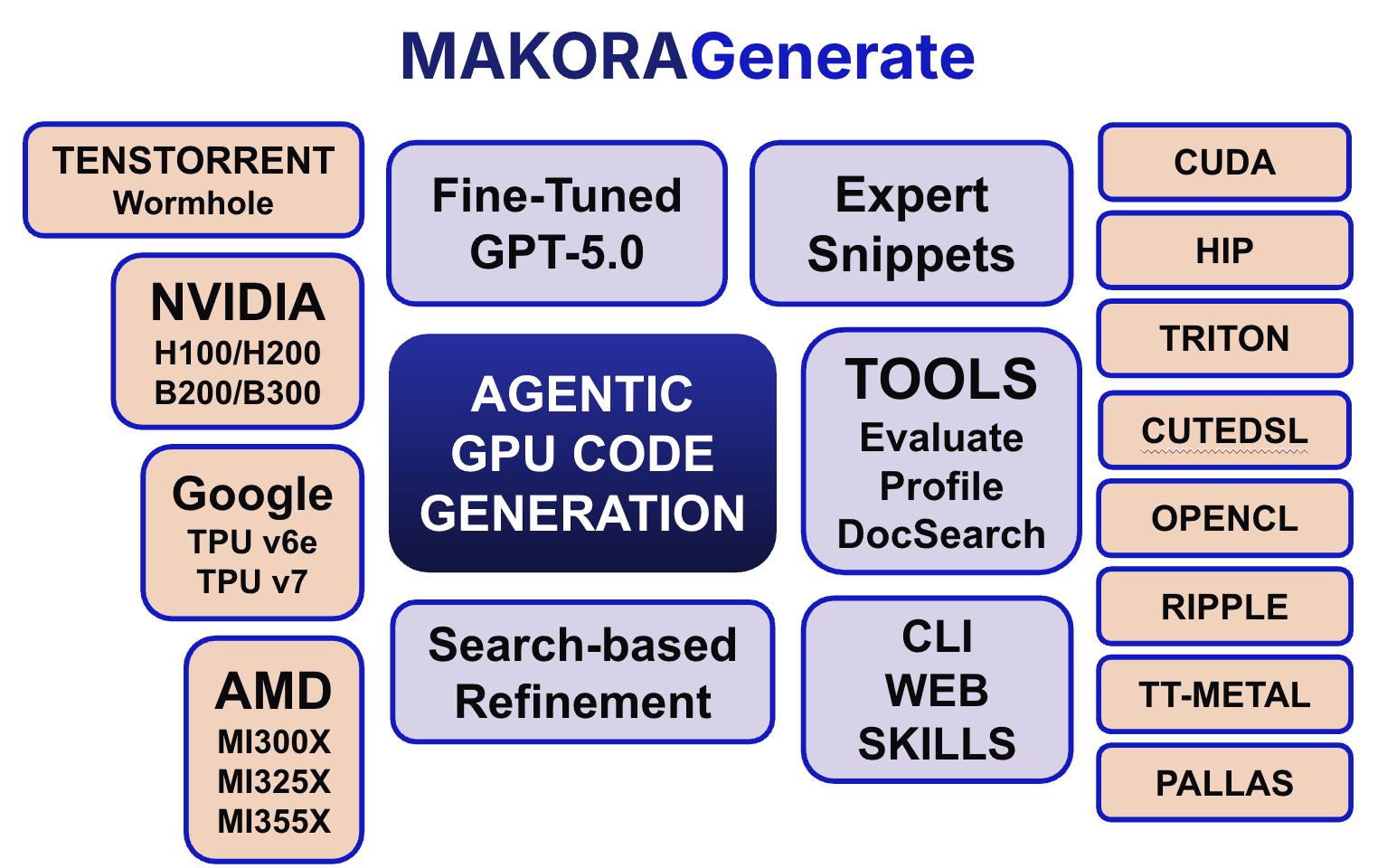
Our solution uses scalable agentic code generation using LLMs, including our own fine-tuned GPT-5 variants [1]. Our product, MakoraGenerate, can be accessed at https://generate.makora.com/, and we have seen multiple successes in rapidly adding support for new models, new hardware, or new algorithms. Furthermore, our automated flow has improved multiple hand-optimized GPU kernels from both NVIDIA and AMD.
Inference Serving Engines

One layer up the stack, inference servers such as vLLM, SGLang, TensorRT-LLM, ATOM, and others, present a lot of opportunities for performance optimizations. In fact, incorrectly setting the server parameters can matter as much as a 10X performance difference! A recent article shows how enterprises are struggling with adapting inference servers to AI workloads [2]. The plot above highlights the large performance design space possible for a single AI model. Navigating that space is non-trivial, yet pivotal for AI performance engineering.
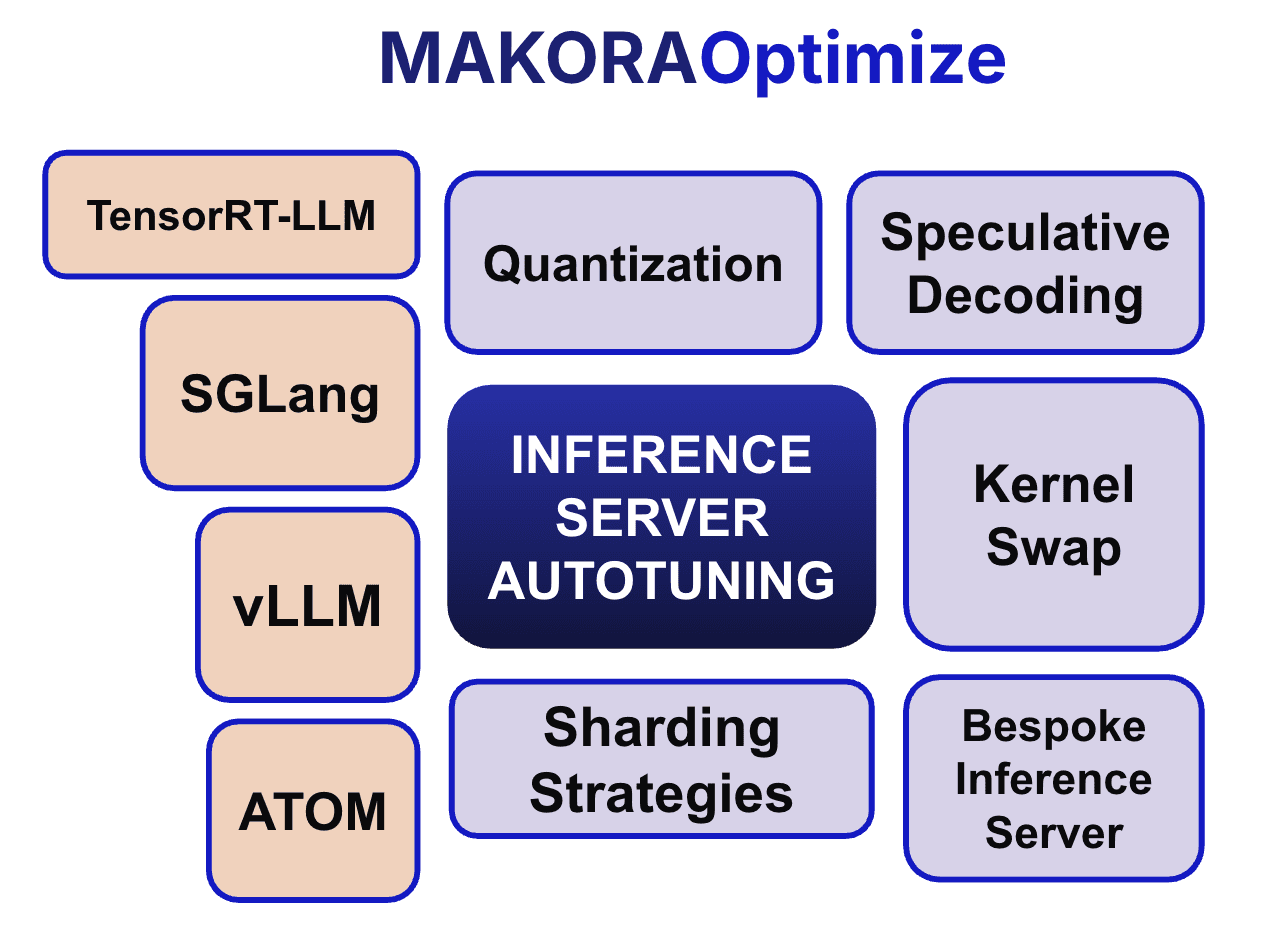
At Makora, we have developed MakoraOptimize to autonomously navigate that large design space, including (1) investigating different model sharding strategies, (2) implementing different quantization and speculative decoding algorithms whilst co-optimizing other serving parameters, and (3) together with MakoraGenerate, swapping in shape-optimized (for batch and sequence length) kernels for maximum performance.
Algorithm Innovation
The AI research community is on fire! There are new papers every day on improving efficiency through algorithm innovation. This includes new quantization schemes, datatype innovations, speculative decoding algorithms, inference algorithms, and more. However, the main blocker to the implementation of these algorithms, is the complexity of the AI performance stack. A new algorithm will inevitably require low-level kernel support, inference server support including scheduling, memory management, and other optimizations to fully realize performance improvements from a new research idea.
A perfect example is our own SMC-SD inference algorithm developed within Makora with collaborators [3]. To realize an implementation for this new algorithm, we needed to significantly modify KV-cache management, add GPU-side resampling kernels, in addition to many other inference server optimizations to overlap CPU and GPU execution (more blog posts on that later!). Without Makora’s automated software stack, it would’ve been impossible to deploy SMC-SD in production so quickly. The power MakoraGenerate and MakoraOptimize shines in deploying new algorithms, and we are hard at work bringing many cool new research ideas into production. The plot below shows that we were able to achieve faster performance using 4xMi325X compared to 576 Groq chips on Llama3.3-70B using SMC-SD and our automated software stack.

Conclusion
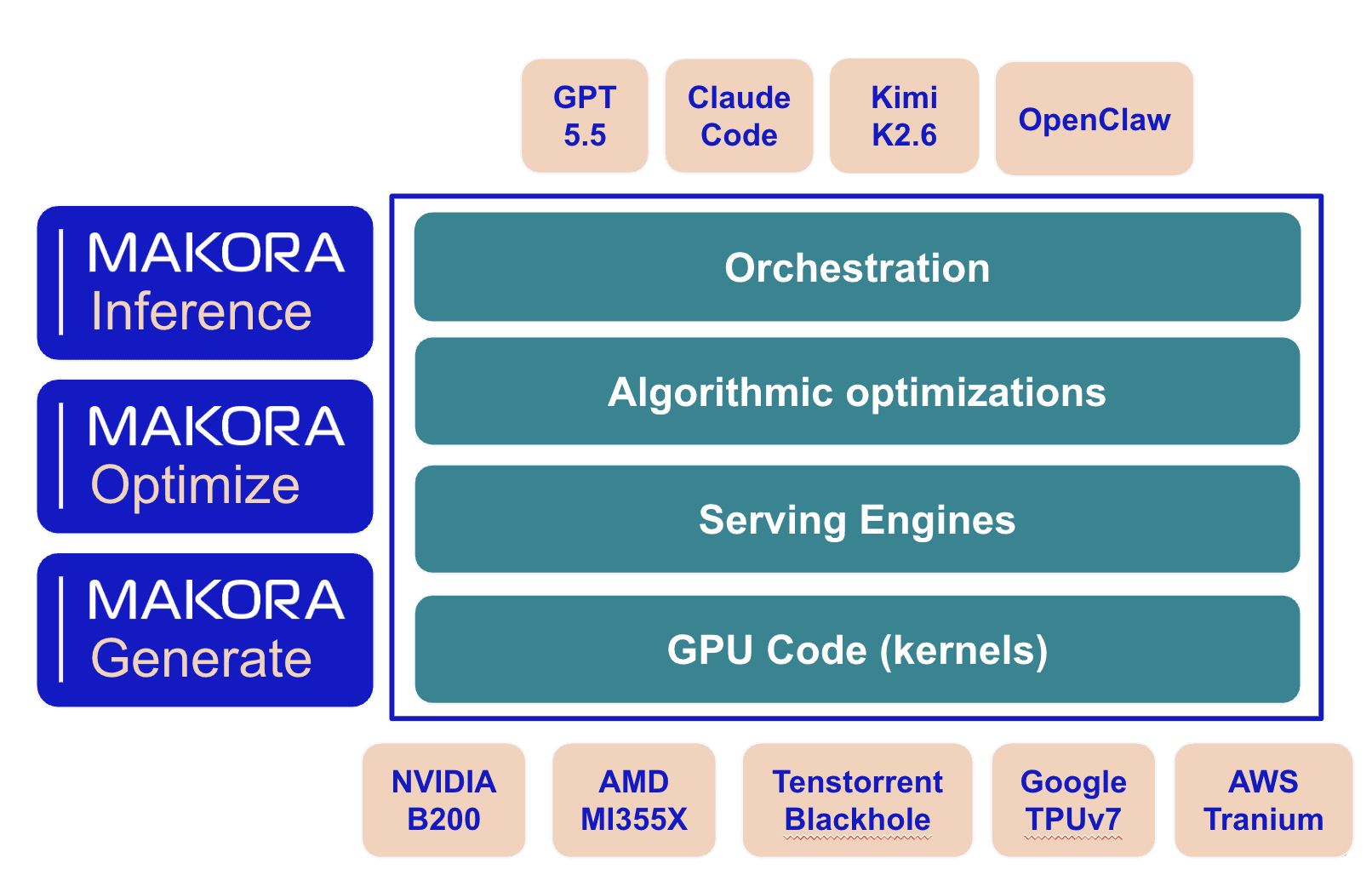
Our automated software stack culminates into MakoraInference, our token serving products for popular AI models that runs on multiple different hardware backends. It is the ultimate test of the efficacy of our performance engineering approach, and it leverages MakoraGenerate and MakoraOptimize for maximum performance. In addition, orchestration and scaling optimizations at the web level, including prefix-cache management, model-level and request-level disaggregation, and optimized load balancing ensure a fast and scalable inference product. It is online and accessible now at https://app.makora.com/.
References
[1] Tehrani, Ali, Yahya Emara, Essam Wissam, Wojciech Paluch, Waleed Atallah, and Mohamed S. Abdelfattah. "Fine-Tuning GPT-5 for GPU Kernel Generation." arXiv preprint arXiv:2602.11000 (2026).
[2] Business Insider, Emails show Bank of America's struggles with Nvidia AI: 'You have to help us as local car mechanics drive the race car!' https://www.businessinsider.com/bank-of-america-nvidia-ai-internal-emails-2026-1
[3] Emara, Yahya, et al. "Faster LLM Inference via Sequential Monte Carlo." arXiv preprint arXiv:2604.15672 (2026). https://arxiv.org/pdf/2604.15672.
Latest
From the blog
The latest industry news, interviews, technologies, and resources.




